

BY IAN OWNBEY
At Pierre, we transitioned from Supabase's REST API and realtime subscriptions to Replicache's local-first replication framework for our website. There is not a ton of writeups out there about how to actually move to local first, though. After wrestling with it a bit we think we got to a pretty good place technically and have definitely started to see the benefits in iteration speed.
This is a long article documenting how we implemented our client and server side of local-first. We hope it is helpful for anyone interested in local-first development generally or replicache specifically.
Why Replicache?

We explored several options for local-first development. "Local-first" means that most or all data is sent to and stored on the client in an IndexedDB database within the browser. The frontend then directly reads and writes this data, which is subsequently synced to the server. While numerous library options are available (such as ElectricSQLRxDB, and many others emerging almost weekly), we ultimately chose Replicache.
Replicache is essentially a protocol for syncing data and a client library that stores this data in IndexedDB. The implementor is responsible for writing the backend, choosing the backend strategy, and implementing the mutations. Although this approach can be initially daunting, it offers the greatest flexibility—a quality we highly valued as we transitioned an existing codebase.
A key benefit of this architecture is the clear separation of concerns between the backend and frontend. The backend focuses on reading and shipping the data, while the frontend concentrates on presenting it. This separation makes both the frontend and backend code much easier to reason about and iterate on.
Replicache delegates authentication and access control to the implementation, which we consider an advantage. Access control for client-side data can be incredibly complex, and many incremental local-first solutions I've encountered fall short in this area (unless you fully adopt their approach, like Supabase's Row Level Security). The concept of simplifying access control to the API layer struck me as a significant improvement.
Performance Characteristics
To understand the performance characteristics of Replicache on Pierre, let's consider the payload of our own team's workspace. For context, the Pierre team has about 18 months worth of development from a team of 6 – which translates to about 45mb of data that needs to be stored in the browser.
To make the initial load more palatable this data is broken up into multiple requests initially, with the first request (which loads the last 14 days of data which is enough to start using the website) has a p90 of 4 seconds and a p50 of 1 second (this is for the Pierre team who has about 30 branches a week). After that initial request (meaning the first time that browser has loaded the team) every follow up request has a p50 of 200ms and p99 of ~4s. These follow up requests happen in the background, though, and do not impact page load or draw time which feels very nice.
How Replicache Works
Below we try to go into the different parts of how Replicache works, how we use it and what lessons we have learned. It is a lot of information. We try to break it up as best we can moving from loading data to mutating data.
At its core, Replicache is an in-browser key-value store built on IndexedDB. It fetches data by periodically polling (or on-demand polling) a `/pull` endpoint. This endpoint can respond with three different operations:
{op: "clear"}to delete the entire local database{op: "del", key: "user/1234"}to remove a specific key-value pair (in this case, "user/1234"){op: "set", key: "user/1234", value: {id: "1234", name: "Jacob Thornton"}}to add or update a key-value pair
These operations are returned in an array and applied to the local database sequentially.
The /pull endpoint's primary goal is to ensure the client has all necessary data. In its simplest form, this could be a clear operation followed by set operations for each key-value pair. An even simpler approach—suitable when data is never deleted—would skip the clearoperation and just use set for all data, as Replicache overwrites existing values.
However, with large datasets, this approach becomes inefficient. The challenge lies in minimizing data transfer during each /pull request while ensuring all changes since the client's last request are sent. This strategy keeps the client's data current without overloading the database or network with unnecessary transfers.
To achieve this, the /pull endpoint must track what data the client already has and what it needs. Implementing this logic is the most complex aspect of creating a Replicache backend.
State and Cookies
Replicache uses a cookie parameter sent to the /pull endpoint to manage data synchronization. This parameter contains the cookie value returned by the previous /pull request (or null for the client's first pull).
The cookie must include an order value—an always-incrementing number. This requirement, though not well-documented, is crucial; failing to consistently increase it leads to unexpected behavior. You can add other desired values to the cookie as well.
Here's an example of our cookie structure:
{
order: requestCookie.order + 1,
changedBranchMaxVersion: 1234, // The maximum version loaded on the last pull
// The below values are for
// initial incremental backfill which is discussed later
lastStatus: "BACKFILL COMPLETE", // The status of the backfill
initialLoadMinVersion: 0, // The last version loaded of the backfill
}Until we explore incremental loading, changedBranchMaxVersion is the key value here.
In essence, you should include in this cookie any information that helps you determine what data the client already has and what new data you need to send.
Pulling Data
In practice Pierres data structure is pretty straight forward. There are:
- Users
- Teams (which have many users)
- Repos (which belong to a team)
- Branches (which belong to a repo)
- Comments, jobs, annotations, etc. (which belong to a branch)
To optimize data transfer, we track two integers called version. One is associated with a Team and increments whenever there's an update to a branch or any of its associated elements. The second version is on a Branch and is set to the Team's version whenever that branch is updated.
In the cookie, we track the Team's version from the last/pull request. On subsequent requests, we only return branches with aversion higher than this. This ensures we only send data for branches that have actually been updated.
For Users, Teams, and Repos, we currently send all data on every /pull request. While not optimal, this works for now as teams tend to be small. If data volume becomes an issue, we can implement versioning for Repos or user team memberships to send updates only when necessary.
Database Transactions
Quickly it is worth mentioning that it is EXTREMELY IMPORTANT that when our API thinks it has sent all necessary data to the client it is actually right. This is because it is possible it will never ever re-send that data again, which means the client will never get to see that data. To do this you need to rely on database transactions, specifically the REPEATABLE READ isolation level in postgres. What this means is that postgres promises all of the data you are reading has not changed for the duration of the transaction. If any of that data does change it will cancel the transaction (and you then retry it again). You might consider this an "optimistic lock" in other database contexts.
We rely on this along with a version column on Team which gets incremented on any write to any branch on that team to make sure that we know the maximum version number to return in the cookie.
In practice this looks like wrapping all of our sql calls in (we usepostgres.js):
export const tx = async <R>(sql: SQL, f: (sql: TransactionSql) => R) => {
for (let i = 0; i < 10; i++) {
try {
return await sql.begin("TRANSACTION ISOLATION LEVEL REPEATABLE READ", f);
} catch (error) {
if (error instanceof postgres.PostgresError && error.code === "40001") {
console.warn(`SERIALIZATION FAILURE, RETRYING ${i}`, error);
continue;
} else {
throw error;
}
}
}
console.error("SERIALIZATION EXCEPTION");
throw new Error("SERIALIZATION EXCEPTION");
};
export const pull = (teamId: string, previousVersion: number) => {
return await tx((sql) => {
const team = await sql`SELECT * FROM teams WHERE id = ${teamId}`
const branches = await sql`SELECT * FROM branches WHERE version > ${sql(previousVersion)}`
// ... Convert branches into replicache operations
})
}
Data and Models
Defining data models with a validation library like Zod has been one of the most valuable decisions in our codebase. While Zod itself can be slow—and we wouldn't necessarily recommend it specifically—using some form of data validation is crucial. Once data reaches the client, it's there to stay. You need to ensure it's structured as expected and be mindful of any changes you make to that structure.
We share these models between the client and API, which has proven immensely beneficial. This approach ensures both sides agree on the data's shape, with validation occurring on the API side. We implement this using a moonrepo, but you could achieve similar results by writing your API within Next.js route handlers or using a shared package.
Our models package also serves as an ideal location for client-side Replicache data reading methods and, later, mutations. For instance, our `BranchModel.ts` looks something like this:
export const BRANCH_LIST_KEY = 'branch/';
export const branchKey = (id: string) => `${BRANCH_LIST_KEY}${id}`;
export const branchSchema = z.object({
id: z.string(),
created_at: z.string(),
name: z.string().nullish(),
title: z.string().nullish(),
// ...
});
export type BranchModel = z.infer<typeof branchSchema>;
export const getBranch = async (tx: ReadTransaction, id: string): Promise<BranchModel[]> => {
return tx.get(branchKey(id));
};
To simplify this you can also use https://github.com/rocicorp/rails which will generate these boilerplate getters and setters for you.
Many people recommend running the fetched object through branchSchema.parse (the zod parse & validation function) on the client but we found this to be too slow in practice especially when listing many branches. Although the added safety would be nice if you didn't feel the speed hit was too bad depending on how much data you are fetching.
Putting it all together
So once we have all of this together we end up with something that looks roughly like
export const pull = async (
teamId: string,
body: { cookie: Cookie | null; } | null,
) => {
return await tx(db, async (sql) => {
const patch: PatchOperation[] = [];
const cookie = body?.cookie || null;
if (!body || !cookie) {
console.log("Bad cookie, resetting");
patch.push({
op: "clear",
});
}
const users: Set<string> = new Set();
const [{ team, version: teamVersion }, repos] = await Promise.all([
sql`SELECT teams.*, json_agg(team_users.*) as members
FROM teams JOIN team_users ON teams.id = team_users.team_id
WHERE teams.id = ${teamId}`,
sql`SELECT * FROM repos WHERE team_id = ${teamId}`
]);
patch.push({
op: "put",
key: teamKey(team.id),
value: teamSchema.parse(team),
});
team.members.forEach(({ user_id }) => {
users.add(user_id);
});
repos.forEach((repo) => {
patch.push({
op: "put",
key: repoKey(repo.id),
value: repo,
});
});
const branches =
cookie?.changedBranchMaxVersion
? sql`SELECT * FROM branches WHERE repo_id IN (${sql(repos.map(({id}) => id))}) AND version > ${cookie.changedBranchMaxVersion}`
: sql`SELECT * FROM branches WHERE repo_id IN (${sql(repos.map(({id}) => id))})`
branches.forEach((branch) => {
patch.push({
op: "put",
key: branchKey(branch.id),
value: branchSchema.parse(branch),
});
}
const profiles = await sql`SELECT * FROM profiles WHERE id IN ${{sql(users.values())}}`
profiles.forEach((profile) => {
patch.push({
op: "put",
key: profileKey(profile.id),
value: profileSchema.parse(profile),
});
})
return {
cookie: {
order: (cookie?.order || 0) + 1,
changedBranchMaxVersion: team.version,
},
patch,
}
});
};
This isn't exactly what our code is but is a close approximation. This is also missing some things like confirmed mutations (which we will talk about in the/push endpoint section) and deletions.
A side note on testing
I feel like API's are often pretty easy to write tests for, but one huge benefit of the replicache protocol is it is EXTREMELY easy to write tests for. This is important because if your API sends bad data by accident you need to clear everyone's store to get rid of it. It is also important because 500's dont actually surface to the user, the replicache client will just keep retrying the/pull API endpoint with a exponential backoff. So it becomes very hard to tell what is the difference between a bad deploy/codepath and a clientside bug even if you are just developing.
Deletions

A quick note on deletions: If something gets deleted in our database we need to make the client aware, which means we need to know whether we have already told the client about the delete. The replicache docs suggest doing "soft deletes" where you add a "deleted" flag to rows and use that to know. We have in the past found this extremely cumbersome (and very annoying to make GDPR complaint) so instead we keep a table of deletes which has an ID, the table, the team and a version.
We read from this on any pull and send any new deletions down to the client. If we felt better about using hooks and things in postgres this would probably be pretty easy to make happen automatically. Instead we implemented it in the /pushendpoint which is a little more cumbersome but not too bad.
Client side
OKAY that was a lot. What we now have is a /pull endpoint which will initially return all of the branches and then after that return any new or changed branches on subsequent pulls.
Lets start talking about the client. This is where the majority of Replicache's code comes in. This isn't going to be a deep dive on how it works, which because it is closed source is a bit of a mystery, but instead a practical walkthrough of how we implemented our client and why we did it that way.
The basic interface for reading data from Replicache is `useSubscribe` from the https://github.com/rocicorp/replicache-react package. This takes a function which in turn takes a `ReadTransaction` and returns some data. The function is re-evaluated when data changes, and that triggers a react re-render if the result changes.
const branch = useSubscribe(rep, (tx) => getBranch(tx, branchId), {
default: undefined,
dependencies: [branchId],
});
To make this slightly easier we keep the Replicache instance in a top-level context and define our own `useSubscribe` hook which takes a function and gets that replicache instance off of the context.
import { UseSubscribeOptions, useSubscribe as useRepliSubscription } from 'replicache-react';
// ... Context
export function useSubscribe<QueryRet, Default = undefined>(
query: (tx: ReadTransaction) => Promise<QueryRet>,
options?: UseSubscribeOptions<QueryRet, Default>,
): QueryRet | Default {
const { rep } = useContext(Context);
return useRepliSubscription(rep, query, options);
}
Flashing
We found that Replicache does do a lot of work to try to run an initialuseSubscribe query on first render to limit flashing. Unfortunately once you start nesting useSubscribe calls in components which are in other components that have there own useSubscribe it is possible to get a waterfall like effect of flashing. These flashes are often only for 1 or 2 renders but they can really hurt the feeling of "instant" which you are doing all of this work for.To try to avoid this you can fetch as much data as you want in a useSubscribe and we often do that. We will fetch branches, comments, whatever is necessary to populate a list at the top level and then use a context to drive the UI.
const RecentBranchesList = () => {
const { branches, comments, replies } = useSubscribe((tx) => {
const branches = listBranches(tx).filter((branch) => inLastWeek(branch.createdAt))
const branchIds = branches.map(({id}) => id)
const [comments, replies] = await Promise.all([
Promise.all(branchIds.map((id) => listBranchComments(tx, id))),
Promise.all(branchIds.map((id) => listBranchReplies(tx, id))),
]);
return { branches, comments.flat(), replies.flat() }
}
// iterate over branches and render the list
}
Initializing Replicache
Actually configuring Replicache is pretty straightforward. The two main things it takes is a pull url (the API endpoint described in the previous section), a push endpoint (which we will explain in the next section) and an auth token. The more important parts are schemaVersion and name.
Our replicache is configured like:
return new Replicache({
name: `${userId}/${branchId ? branchId : teamId}`,
licenseKey: '<your license key>',
pullURL: `${URL}/pull?teamId={teamId}${branchId ? `&branchId={branchId}` : ''}`,
pushURL: `${URL}/push?teamId={teamId}${branchId ? `&branchId={branchId}` : ''}`,
mutators: mutators,
auth: authToken,
pullInterval: null,
pushDelay: 1000,
schemaVersion: '3',
indexes,
});
name
The name is a unique string to the user, it is what links all of a user's replicache clients together across browsers and tabs. Usually you can just use a userId. We have essentially multiple stores: one for a team and another for any non-team shared branches you go to. Replicache will delete unused stores after about 2 weeks, essentially garbage collecting ones that arent used.
schemaVersion
The schemaVersion argument is used as a way of versioning the client to the backend. It is sent with every request, and the indexedDB name used is a combination of name and schemaVersion. This means a fresh indexedDB will be generated ifschemaVersion changes.
We have found this useful when significantly changing the schema shape, or to kind of feature-flag specific parts of the data on for development and things like that. It isn't something you have to worry too much about but is a useful tool to know about as a codebase evolves.
Auth
We initially pass the auth token to replicache so that it always has at least one. This gets loaded in React Server Components for us and passed down to the Provider.
For refreshing the access token Replicache has a getAuth function you can set which will get called any time the Replicache client hits a 401 from the server. You can then refresh the token and return a new one which Replicache will start using for future requests.
For example our getAuth uses a supabase client to refresh the session and return the new access token:
const rep = new Replicache({...})
rep.getAuth = () => {
return client.auth.refreshSession().then((resp) => {
return resp.data.session?.access_token;
});
};
Mutators
Mutators are functions used to update the local IndexedDB and notify the backend of changes. When a user initiates a write operation in Replicache, the process unfolds as follows:
- The mutator function executes, writing to the local index.
- Replicache sends the mutator function name and arguments to the backend.
- Once the backend request completes, Replicache re-pulls the data.
- Finally, it rolls back the local mutator function changes and applies the server-returned operations to the store.
This assumes everything works as intended. Mutators only need to update enough data for the UI to appear as if the change has occurred. The server can perform the full update, including any side effects, and the canonical data is returned the next time the client pulls.
For example, when merging a branch on Pierre, the client mutator simply updates a flag on the branch record to mark it as merged. The server mutator does the same but also creates an activity item for the merge.
Another helpful example is our updateProfileSettings function, which allows users to update their email address or avatar. The client mutation is
import { generate } from '@rocicorp/rails';
export const { update: updateProfileSetting } = generate<ProfileSettingModel>('profile_setting');
export const mutators = {
updateProfileSetting: async (
tx: WriteTransaction,
args: z.input<typeof profileSettingUpdateSchema>,
) => {
await updateProfileSetting(tx, profileSettingUpdateSchema.parse(args));
},
};
which updates the local record with the new settings. While on the server the actual mutation is
.on("updateProfileSetting", async (args) => {
assertUsersMatch(args.id, user.id);
await updateProfileSetting(sql, profileSettingUpdateSchema.parse(args));
if (args.email) {
await supabaseAdmin.auth.admin.updateUserById(args.id, {
email: args.email,
});
}
})
We also update supabase which we use for auth and will fire off an email confirmation message.
Which mutators to implement
The obvious default (and what we initially implemented) is to have simple record update mutators like updateBranch, deleteRepo, andsetComment. While these are useful, I've discovered that it's often better to have mutators that reflect user actions. Instead of callingupdateBranch({id: "123", isMerged: true}) when someone merges, it's preferable to havemergeBranch({id: "123"}). This approach allows server mutators to be more comprehensive and eliminates the need for the client to know how to update records directly.
For example, when merging a branch on Pierre, the client mutator simply updates a flag on the branch record to mark it as merged. The server mutator does the same but also creates an activity item for the merge.
On failed mutations

If a mutation fails to reach the server (for example, due to a user closing their browser) or encounters an error (such as server downtime), Replicache will persistently reapply the local mutation after each pull and continue resending it to the /push endpoint until confirmation. In theory, this means someone could merge a branch (triggering the client to merge it via the git-api) and then close their browser before we update the database and notify other clients of the merge. However, this hasn't been a significant issue in practice. The push endpoint is relatively quick, and users rarely perform an action and immediately shut down their computer or close their browser.
During development, if the /push endpoint is failing, it won't be immediately apparent to users or developers without checking the network tab for errors. This underscores the importance of robust data validation. If we inadvertently modify the client to send invalid data during development, Replicache will continue reapplying this bad data locally, creating the illusion that everything is functioning correctly. In reality, the mutation remains unconfirmed and ineffective.
Consequently, comprehensive logging and notifications are crucial, especially for/push errors. We've found https://axiom.co/ to be valuable for this purpose, though similar functionality can be achieved with other observability platforms like Datadog.
Sharing mutation code between backend and frontend
The Replicache docs talk a bit about sharing mutator code between backend and frontend but honestly it does not make much sense to me. You have to worry about things like auth and access control as well as side effects.
The thing you definitely do want to do though is share types between the client mutators and the /push endpoint. This way you know and can enforce what arguments are passed to each mutation and that your /push endpoint is handling all of the mutators.
The way we do this is by keeping our client mutators in the same package as the models. So in our internal @pierre/models package we have
export const mutators = {
setComment: (tx: WriteTransaction, comment: CommentInput) => {
return setComment(tx, commentInputSchema.parse(comment));
},
updateComment: (tx: WriteTransaction, comment: CommentUpdate) => {
return updateComment(tx, comment);
},
deleteComment: async (tx: WriteTransaction, id: string) => {
await deleteComment(tx, id);
const promises: Promise<any>[] = [];
for await (const reply of tx.scan<z.infer<typeof replySchema>>({ prefix: REPLY_LIST_KEY })) {
if (reply.comment_id === id) {
promises.push(deleteReply(tx, reply.id));
}
}
await Promise.all(promises);
},
// ... etc etc
};
With this you can use this crazy type on your server to then pull out the argument types
type MutatorArgs<Key extends keyof typeof mutators> = Parameters<(typeof mutators)[Key]>[1];
const setComment = (args: MutatorArgs<'setComment'>) => {
//...
};
or something similar.
Server Push
The server side of mutators are responsible for three things.
- Update the database to reflect the new state.
- Bump the version number on the branch and the team.
- Track the mutation ID so it can be confirmed to the client that it has ran.
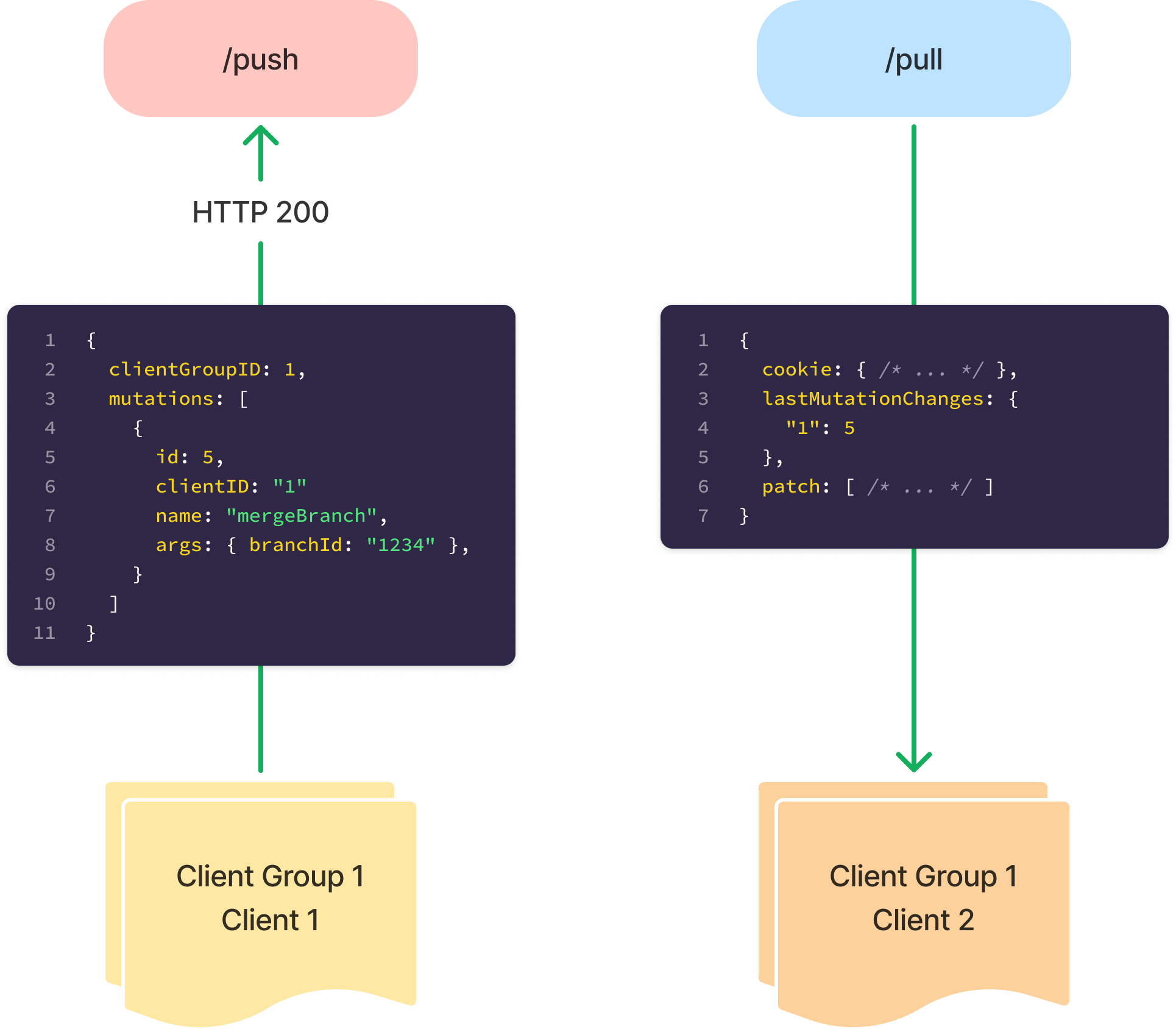
Replicache clients have two identifiers: A client ID and a client group ID. The client ID is associated with each specific instance of Replicache. This most often means each tab. A client group reflects an indexeddb database which usually means a browser.
Every individual client is associated with a mutation by a mutation ID which is an incrementing number. When any client from a client group makes a request to/pull the server responds with the latest mutation ID ran for every client in that group. This is because one tab can do a request to /pushbut another tab might do the next /pull .
If a mutation is not successful, for example there is an Internal Server Error (500) or for any reason a mutation is not confirmed on the next /pull then that mutation will continue to be sent on future calls to the /push endpoint.
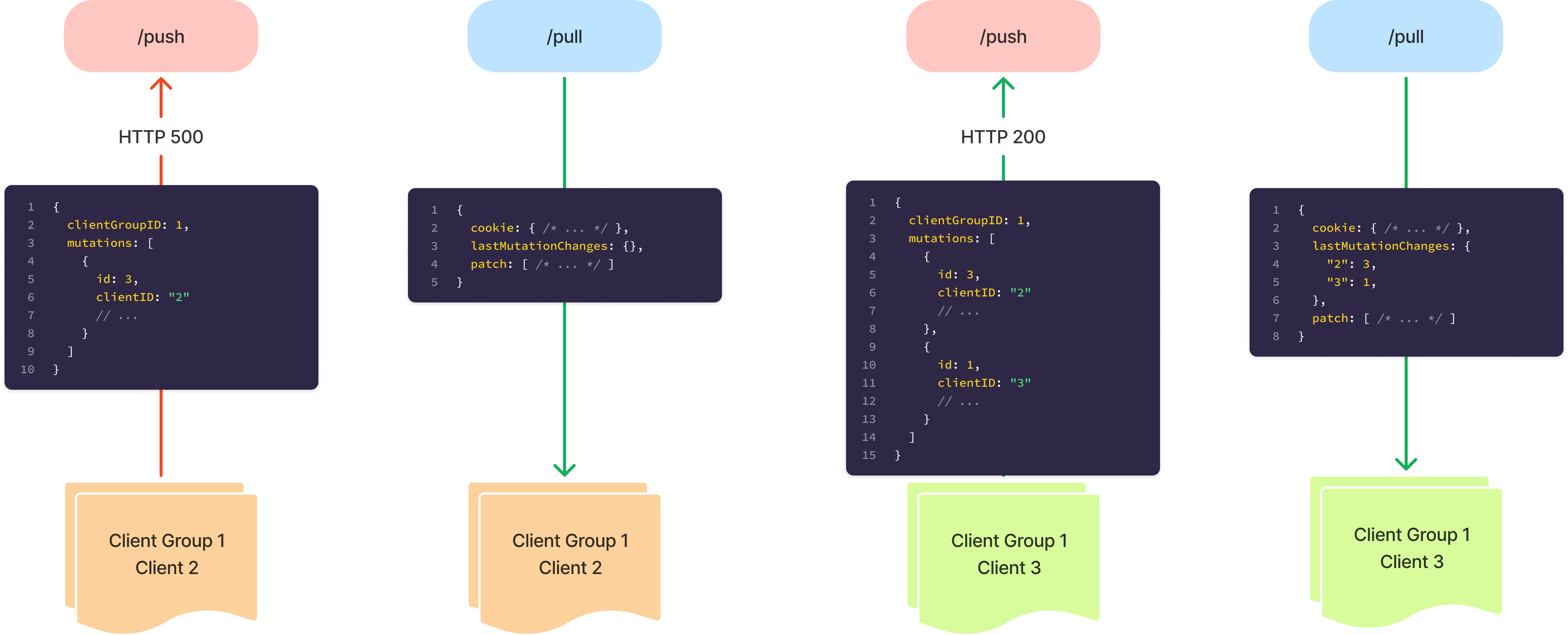
Tracking client mutations
We track client mutations via 2 additional tables. One is to track client groups and the other to track clients.

The client group is associated with a team because that is what has the most recent version number associated with it.
At the start of our /push endpoint we need to first open a transaction and then fetch the client:
const fetchClient = async (sql: SQL, groupId: string, clientId: string) => {
const [client] = await sql`
SELECT * FROM replicache_clients WHERE
id = ${clientId}
AND client_group_id = ${groupId}
`;
return client;
};
Once we have that we set our next mutation ID and version
const nextMutationId = client.last_mutation_id + 1;
const nextVersion = team.version + 1;
With this we can now do the actual mutations.
Parsing Mutations
We wrote the following helper to make parsing mutations easier, it can definitely use improvement. We would like to make it so all mutations don't need to exist in a single file, for example.
import type { MutationV1, MutatorDefs } from 'replicache';
type HandledCallback = (method: string) => void;
type ErrorCallback = (method: string, e: unknown) => void;
export class MutationParser<Mutators extends MutatorDefs> {
mutation: MutationV1;
handled = false;
promise: Promise<void> | undefined;
onHandled: HandledCallback = () => {};
onError: ErrorCallback = () => {};
constructor(
mutation: MutationV1,
options: { onHandled?: HandledCallback; onError?: ErrorCallback },
) {
this.mutation = mutation;
if (options.onHandled) {
this.onHandled = options.onHandled;
}
if (options.onError) {
this.onError = options.onError;
}
}
on<Key extends keyof Mutators>(
method: Key,
callback: (args: Parameters<Mutators[Key]>[1]) => Promise<void> | void,
) {
if (this.mutation.name === method) {
this.handled = true;
this.onHandled(method);
try {
const resp = callback(this.mutation.args as any);
if (resp instanceof Promise) {
this.promise = resp.catch((e) => {
this.onError(method, e);
throw e;
});
}
} catch (err) {
this.onError(method, err);
throw err;
}
}
return this;
}
resolve() {
return this.promise || Promise.resolve();
}
}
We then use this class in the actual /push endpoint like
import { mutators } from '@pierre/models';
const parser = new MutationParser<typeof mutators>(mutation, {
onHandled(method) {
logger.event({ mutation: method });
},
onError(method, e) {
logger.error({ mutation: method }, e);
},
});
parser.on('setComment', async (args) => {
const comment = commentInputSchema.parse(args);
assertUsersMatch(user.id, comment.user_id);
await authBranchIsAccessible(sql, comment.branch_id, user.id, true).then(() =>
createComment(sql, comment),
);
await bumpBranchVersion(args.branch_id);
});
if (!parser.handled) {
throw new NonRetryableError(`Unknown mutation: ${mutation.name}`);
}
await parser.resolve();
The most helpful part of this is that it uses the types of the mutators in our models package which I described above. This way if a signature changes typescript will make us aware that the server needs to change how it handles that mutation.
Access Control
We found the easiest way to do access control was by having some helper functions like assertUsersMatch or authBranchIsAccessible which can then be used inside of the mutations. Trying to generalize this became too indirect for something as important as access control (anyone can send arbitrary JSON to the this endpoint as long as they have a valid auth token).
Tracking mutations
Finally we need to track the mutation ID on the client row so it can be returned in the next /pull with that client:
await sql`
UPDATE teams SET version = ${nextVersion} WHERE teams.id = ${team.id}
`;
await sql`
INSERT INTO replicache_client_groups ${sql({ id: clientGroupId, user_id: user.id, team_id: team.id }, 'id', 'user_id', 'team_id')}
ON CONFLICT (id) DO NOTHING;
`;
logger.log(
`Updating client ${client.id} group: ${client.client_group_id} to ${nextMutationId} version: ${nextVersion}`,
);
await sql`
INSERT INTO replicache_clients
(id, client_group_id, last_mutation_id, last_modified_version)
VALUES
(${client.id},
${client.client_group_id},
${nextMutationId},
${nextVersion})
ON CONFLICT (id) DO
UPDATE SET
last_mutation_id = ${nextMutationId},
last_modified_version = ${nextVersion}
`;
To confirm which mutations have been run to the client, the /pull endpoint returns the mutation ids for that client group (I do this as a single query but it is not really necessary):
const [clientGroup] = await sql`
SELECT
replicache_client_groups.*,
COALESCE(json_agg(replicache_clients.*), '[]') as clients
FROM
replicache_client_groups
LEFT JOIN replicache_clients ON replicache_clients.client_group_id = replicache_client_groups.id
WHERE
replicache_client_groups.id = ${groupId}
AND replicache_clients.last_modified_version > ${version}
GROUP BY replicache_client_groups.id
`;
const lastMutationIDChanges = clientGroup.clients.reduce<Record<string, number>>((prev, curr) => {
prev[curr.id] = curr.last_mutation_id;
return prev;
}, {});
And return any last_mutation_id that has run since the last version to the client:
const resp: PullResponse = {
cookie: nextCookieResp,
lastMutationIDChanges: lastMutationIDChanges || {},
patch,
};
return resp;
Incremental Backfilling
The first time a client group does a request to /pull (meaning if the cookie is null) we will present the user with a spinner in the client and initially send the last 14 days of data to them. The client then continues requesting data in chunks until it has successfully loaded all of the data for that team. Ideally this only happens once per browser in its entire lifetime.
We accomplish this in a very similar way to the Replicache examples. It starts by tracking a new property on the cookie called initialLoadMinVersion which holds the minimum version number that has been backfilled. It is the minimum so that we can load data from the most recent to the oldest for the best user experience. We also store "lastStatus" which is either null (when they are doing the first request), INITIAL_LOAD or BACKFILL_COMPLETE.
export type Cookie = {
order: number;
lastStatus: Status;
changedBranchMaxVersion?: number;
initialLoadMinVersion?: number;
};
When a client group makes a request to /pull we fetch branches in two batches. The first batch includes any newly changed branches since the last request (described earlier in this post). The second batch occurs if their request cookies status isINITIAL_LOAD or null we query for 500 branches with version < cookie.initialLoadMinVersion ordered by highest version first.
On these requests that are backfilling we also add a special key to the patch which has the key of meta/partial_load and the value of
patch.push({
op: 'put',
key: 'meta/partial_load',
value: {
endKey: Date.now(),
status: nextCookieResp.lastStatus,
},
});
endKey is a key used to have react rerun a useEffect andstatus is whether the client needs to keep backfilling after this request or not.
Client Backfilling
Then the client does the initial request as normal. In the StoreProvider we use the following hook:
export const usePartialSync = (rep: Replicache) => {
const partialSync = useSubscribe(rep, (tx) => tx.get('meta/partial_load'));
useEffect(() => {
if (partialSync && partialSync.status === 'INITIAL_LOAD') {
rep?.pull();
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, [partialSync?.status, partialSync?.endKey, rep]);
return partialSync?.status;
};
What this does is every time endKey changes (which is changed by every request to/pull ) if the sync status is set to INITIAL_LOAD it will immediately kick off another pull request. This hook is then used to let the frontend know if the status of backfilling is complete or not, which we use to show a spinner in the corner of the website which alerts the user that data is still being backfilled.
Lessons Learned

There are a couple of other pieces to our implementation like public branches and deletions which I haven't gone into here because this is probably long enough already.
Generally this transition has been very successful. Debugging issues, even when people have local data, has not been too difficult largely due to over-logging information on server requests. The frontend code has been able to be drastically simplified which is great, and the latency improvements are hugely beneficial. Our biggest complaint is probably that we haven't been able to put enough into Replicache. Things like Diffs take up way too much space and so we still request them from the server which can make things feel slow.
Even if you aren't using Replicache we would definitely recommend trying a local first approach. I could imagine it being a little hard if the shape of your data has not yet been determined but generally product development is able to go much faster and allow for experimenting with different ideas much easier.
If you have any questions or comments feel free to reach out on Twitter / X or join our Discord.